최근에 데이터 인프라팀으로 팀을 옮기기도 했고, 그동안 AWS Aurora를 사용하면서 생각보다 MySQL과 다른 부분이 많이 있어서 정리가 필요하다고 생각이 됐습니다. AWS의 공식문서를 정리하면서 저의 생각이나 경험을 약간씩 추가하였습니다. 그리고 마지막에는 MySQL(or AWS RDS MySQL)과 다른 점을 정리해보면서 다시 한번 AWS Aurora를 살펴보려고 합니다.

Introduction
Amazon Aurora는 MySQL 및 PostreSQL과 호환되는 완전 관리형 관계형 데이터베이스입니다.
아마존에서는 일부 워크로드를 통해서 기존보다 MySQL 같은 경우는 Throughput(처리량)을 5배 PostreSQL은 최대 3배까지 성능을 높일 수 있다고 설명하고 있습니다. (그대로 믿으면 안 되겠지만 더 성능이 좋다! 정도로 생각하면 좋을 것 같습니다.)
Aurora는 고성능 스토리지 sub system을 포함하고 있습니다. MySQL 및 PostgeSQL 호환 데이터베이스 엔진은 빠른 분산 스토리지를 활용하도록 customized 되어 있다고 합니다.
기본 스토리지는 필요에 따라 최대 64TB까지 자동으로 증가합니다. 그리고 Aurora는 또한 데이터베이스 클러스터링 및 복제를 자동화를 지원합니다. 클러스터링 및 복제는 일반적으로 데이터베이스 구성 및 관리에서 가장 어려운 부분입니다.
Aurora와 기존 RDS(MySQL, PostreSQL)가 어떻게 관련되어 있는지 살펴보면 아래와 같습니다.
- Amazon RDS를 생성할 때 DB Engine으로 Aurora선택 가능
- RDS와 비슷한 Interface (Console 및 CLI)
- Aurora에서는 개별 데이터베이스 인스턴스 대신 전체 클러스터에 대한 관리 작업이 포함되어 있음.
- RDS의 Snap shot을 Aurora로 가져와서 복원이 가능.
공식문서에서는 Aurora와 관련된 maintenance 팁을 소개하고 있습니다.
Instance Endpoints
Aurora는 cluster endpoint 뿐만 아니라 각 instance의 endpoint를 가지고 있습니다. 그래서 각각의 인스턴스에 대한 진단을 따로 할 수 있고, 인스턴스 별로 발생하는 문제인지 클러스터에서 전체적으로 발생하는 문제인지 확인하고 진단할 수 있습니다.
그리고 각 인스턴스의 End point를 사용해서 인스턴스의 크기를 다르게 하거나 다른 parameter group을 설정하거나 다르게 구성할 수 있습니다.
예를 들면, DB 인스턴스가 여러 개일 경우 통계용 인스턴스로 세팅하고 이에 맞게 parameter들을 세팅할 수도 있습니다. 이럴 경우는 cluster endpoint가 아닌 instance endpoint를 사용해야 합니다. (다른 write/read 용은 cluster endpoint를 사용해야 합니다!)
How Aurora Endpoints work with high availability
고 가용성이 중요한 클러스터에서 read/write connection에 read endpoint write endpoint를 사용해야 합니다. 이렇게 연결함으로써 DB인스턴스의 fail-over시에 대처할 수 있습니다. 만약에 instance endpoint로 연결을 해놓은 경우에는 read_only 변수가 on이 되어 있는 instance가 master instance가 되어서 장애를 유발할 수 있습니다.
Amazon Aurora DB Clusters
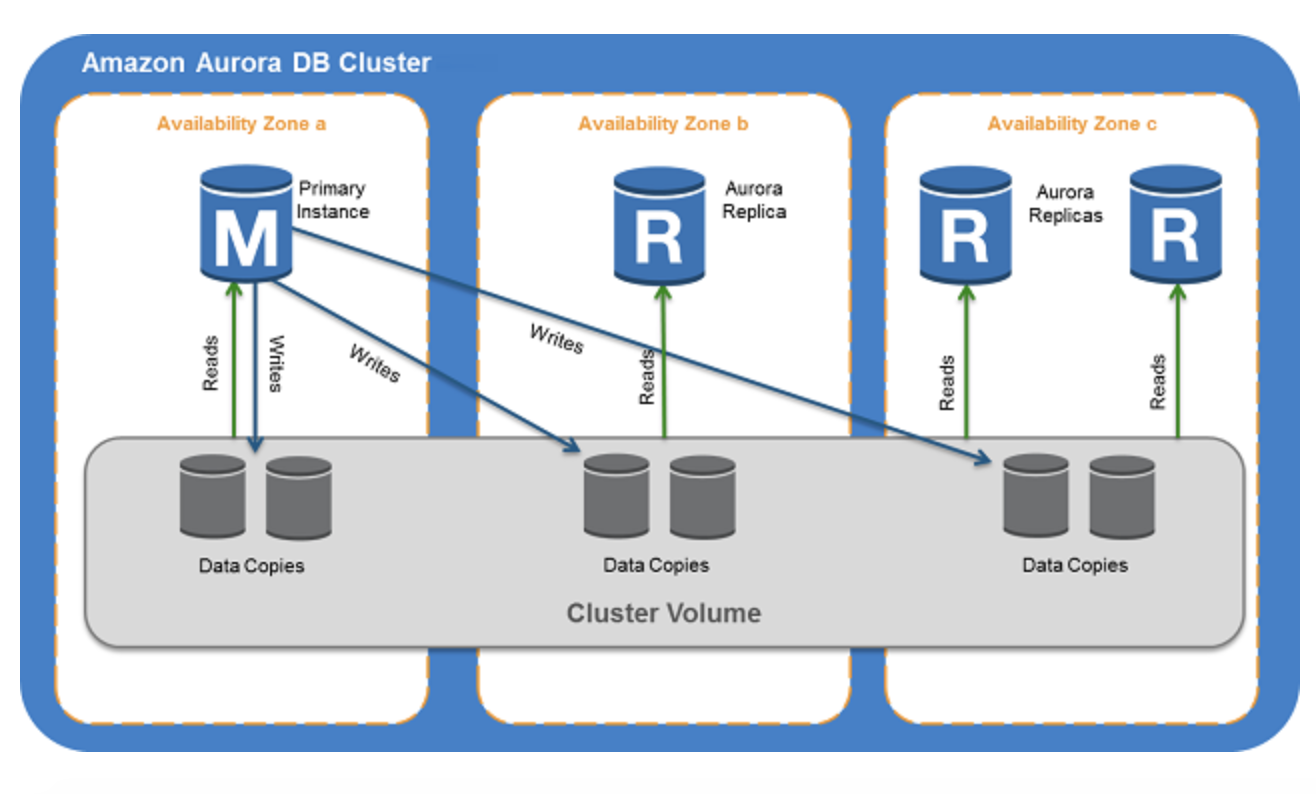
Aurora cluster는 한 개 이상의 DB Instance와 cluster volume으로 이루어져 있습니다. clsuter volume은 그림과 같이 virtual database storage volume으로 각 가용 영역에 데이터의 사본이 있습니다.
Cluster는 두 개의 type으로 이루어진 instance로 구성됩니다.
-Primary Instance
읽기 및 쓰기 작업을 지원, 클러스터 볼륨의 모든 데이터 수정을 실행.
-Replica Instance
읽기 작업만 지원.
(최대 15개까지 복제본 가능, Fail-over시 우선순위를 지정할 수 있음 -> 위에서 특정한 용도로 사용해서 instance endpoint로 사용하고 있는 instance는 당연히 우선순위를 낮춰서 fail-over시 master가 되지 않도록 설정해줘야 합니다.)
여기서 보면 알겠지만 기존 MySQL에는 Replica를 위해서 master node에서 binlog를 dump 하고, replica node의 relay log를 실행시켜서 replication 하지만, Aurora에서는 같은 storage를 사용해서 binlog를 통해 복제할 때 발생하는 성능 손실을 없앴다.
Aurora 엔드포인트 유형
Amazon Aurora Connection Management
엔드 포인트 유형은 다음과 같이 4가지가 있습니다.
-
Cluster endpoint(writer endpoint)
Update, insert, delete 및 DDL 실행 -
Reader endpoint
다수의 instance가 있을 때 load balancing -
Custom endpoint
custom으로 어떤 특정한 목적을 지닌 그룹으로 지정이 가능합니다. -
Instance endpoint
위에서 살펴본 것처럼 특정한 목적을 지닌 인스턴스가 있다면 인스턴스 엔드포인트로 connection을 만들고 처리할 수 있습니다.
사용자 지정 endpoint를 어떻게 만드는지에 대한 가이드 문서
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Endpoints.html
DB Instance Class
참고 문서
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Concepts.DBInstanceClass.html
Amazon Aurora storage and reliability
Overview
Aurora SSD(Solid State Drive)를 사용하는 단일 가상 볼륨인 클러스터 볼륨에 저장이 됩니다. 위에서 소개한 내용처럼 클러스터 볼륨은 AWS 리전에 속한 다중 가용 영역의 데이터 사본으로 구성되어 있습니다. 즉, 해당 리전의 여러 서브넷에 구성되는 것으로 보입니다. 밑에 설명이 있는데 서브넷의 개수와는 상관없이 3개의 가용 영역에 여러 개의 복사본을 보관하고 있다고 합니다.
What the cluster volume contains
Aurora 클러스터 볼륨에는 모든 user data, schema objects, internal metadata (system table, binlog)를 포함합니다. 예를 들면, Aurora는 모든 테이블 그리고 인덱스 그리고 BLOBs, stored procedures 등을 저장합니다.
이러한 Aurora의 공유 스토리지 아키텍처는 데이터를 클러스터의 DB인스턴스와 독립적으로 만듭니다. 예를 들어 새 Instance를 추가할 때 데이터를 복사하지 않으므로 빠르게 추가할 수 있습니다. DB instance를 삭제할 때도 마찬가지로 데이터를 제거하지 않고 클러스터에서 DB 인스턴스를 제거할 수 있습니다. 클러스터를 삭제하는 경우에만 Aurora의 데이터가 제거됩니다.
How Aurora Storage Grows
소개에 쓰여있는 것처럼 데이터베이스의 데이터 용량이 늘어날수록 Aurora 클러스터 볼륨 크기는 최대 64 (TiB)까지 증가할 수 있습니다. 즉, 테이블 크기는 클러스터 볼륨 크기로 제한됩니다.
How Aurora Data Storage is billed
요금은 클러스터 볼륨에서 사용한 공간에 대해서만 청구됩니다. 테이블이나 인덱스가 지워진다고 전체 할당 공간은 동일하게 유지되기 때문에 (추후에 볼륨이 증가할 때 재사용됩니다.) 만약에 큰 테이블들을 지운 경우 비용 절감을 위해서 Cluster를 재생성하는 것도 비용 측면에서 좋은 방법일 수 있습니다. (Online migration후에 테이블이 잔뜩 남아 있을 수 있으니…)
Amazon Aurora Reliability
위에서 살펴본 것처럼 클러스터는 해당 리전의 여러 서브넷에 복제본을 추가해 놓습니다.
그 밖에서도 자동 기능들이 몇 가지 포함되어 있다고 합니다.
- Storage Auto-repair (Aurora는 3개의 가용 영역, Aurora가 디스크 볼륨에서 결함을 자동 감지 및 복구)
- Survivable Cache warming (전원이 꺼진 데이터베이스를 가동하거나 결함 발생 이후 다시 시작할 때 버퍼 풀 캐시를 워밍함)
- Crash Recovery (Aurora는 병렬 스레드에서 비동기 방식으로 충돌 복구를 실행하므로 충돌 직후에도 데이터베이스를 열어두고 사용할 수 있음)
+ 외부 복제(또는 외부 binlog stream에 binlog가 필요하지 않은 경우 binlog_format 파라미터를 OFF 설정하여 이진 로깅을 비활성화하는 것이 좋습니다. 이렇게 하면 복구 시간이 단축됩니다.
Amazon Aurora Security
참고 문서
https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.Security.html
High Availability for Aurora
Aurora 아키텍처는 스토리지와 컴퓨팅을 분리함으로써 일부 혹은 모든 인스턴스를 사용할 수 없는 경우에도 데이터는 안전하게 유지됩니다. 그리고 위해서 본 것처럼 데이터의 복사본이 3개의 가용 존에 저장됩니다. Primary DB인스턴스에 데이터가 기록되면 데이터를 클러스터 볼륨과 연결된 6개의 스토리지 노드에 동기적으로 복제합니다. 이 방법은 데이터 중복을 제공하고, I/O 중지를 없애고, 시스템 백업 중에 지연 시간 스파이크를 최소화합니다.
Replication with Amazon Aurora
DB 클러스터 볼륨은 DB 클러스터의 데이터 사본들로 구성됩니다. 하지만 DB 클러스 터의 기본 인스턴스 및 Aurora 복제본에는 클러스터 볼륨 데이터가 단 하나의 논리 볼륨으로 표시됩니다. 그 결과로 모든 Aurora replications은 replication lag를 최소화하여 쿼리 결과에 대한 데이터를 통일하게 반환합니다.
이제 한 번 그래서 MySQL과 머가 그렇게 다른지 비교해보면서 정리해보겠습니다.
AWS Aurora MySQL VS MySQL
1. Storage Architecture -> Replication
Aurora는 Storage는 로그 구조 저장소(Log-Structuredd Storage)라는 추가 확장이 자유운 저장소 시스템을 사용하고 있습니다. 이 저장소 시스템은 끝부분에 연속해서 업데이트 데이터를 저장해 나갈 수 있어서 잠금으로 인한 대기가 잘 발생하지 않아 MySQL보다 빠른 속도로 데이터를 쓸 수 있습니다. 이로 인한 단편화는 AWS의 스토리지 내부에서 처리된다고 합니다.
Aurora는 Storage를 분리함으로써 Replication에 많은 성능적인 이득을 가져온 것으로 보입니다. Primary Instance에서 Redo log(디스크에 sync 작업을 순서대로 하기 위해서 기록하는 로그)를 보내서 빠르게 변경분을 빠르게 6개의 스토리지 노드에 전달할 수 있습니다. 이를 통해서 기존에 MySQL은 각 노드 별로 스토리지를 가지고 있기 때문에 이를 sync 하기 위해 binlog를 dump 하고 slave node에서 이 dump 한 log를 relay log로 받아서 다시 재실행하지 않아도 됩니다.
2. Management
Cluster 구성을 지원함으로써 읽기 작업에 대한 load balancing을 지원하고, 여러 타입의 end point를 지원해서
관리가 용이합니다. 또한, MySQL에 대한 버전 관리도 어느 정도 AWS에서 개발하기 때문에 관리 요소가 줄어들게 됩니다. 그리고 Aurora는 storage 또한 자동으로 확장되고 사용하고 있는 만큼 비용이 부과되기 때문에 이점 또한 장점이라고 생각합니다.
3. Reliability & Availability
Aurora는 해당 리전의 3개의 가용 존에 2개의 storage를 가지고 있으므로 (총 6개) 더 안전합니다. 그 밖에도 auto fail over 등을 지원하기 때문에 가용성 또한 더 뛰어나다고 볼 수 있습니다.
4. Scalability
RDS MySQL은 각 인스턴스가 독자적인 스토리지를 갖기 때문에 replication 하는데 더 많은 리소스가 필요합니다. 즉, 확장성이 떨어진다고 볼 수 있을 것 같습니다. Aurora에서는 replication을 15개까지 쉽게 늘릴 수가 있습니다. 뿐만 아니라 storage측면에서도 자동으로 64 TiB까지 확장이 됩니다.
여기까지 Aurora에 대해서 공식문서를 살펴보고 정리한 후 MySQL과 Aurora MySQL을 비교하면서 마무리해봤습니다. 혹시, 제가 잘못 알고 있거나 이해가 안 가는 부분이 있으면 남겨주세요!
앞으로 Aurora와 관련된 글을 2~3개 더 정리해보면서 공부해 볼 생각입니다.
감사합니다!
아래 문서를 참고하였습니다.
참고 문서
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/CHAP_AuroraOverview.html
What Is Amazon Aurora? - Amazon Aurora
What Is Amazon Aurora? Amazon Aurora (Aurora) is a fully managed relational database engine that's compatible with MySQL and PostgreSQL. You already know how MySQL and PostgreSQL combine the speed and reliability of high-end commercial databases with the s
docs.aws.amazon.com
https://notemusic.tistory.com/69
AWS Aurora란? [1탄 - RDS MySQL과 AWS Aurora의 큰 차이점]
항상 시작만 하고 제대로 끝마무리를 짓지 못한 상태로 티스토리를 이어가는 것 같습니다. 또 오랜만의 글인데요. 이번에는 Aurora에 대한 글입니다. AWS 상에서 Aurora를 구성하고 또 운영하시는 분들이 한국내에..
notemusic.tistory.com
'Computer Engineering > AWS' 카테고리의 다른 글
| AWS Elastic beanstalk 배포 시 redirect http to https (how to redirect http to https in elastic beanstalk) (0) | 2018.05.17 |
|---|---|
| AWS Lambda 파이썬 라이브러리 패키징 ( Python library packaging) (1) | 2017.12.14 |